Notes from the AWS + Chef Dev Day Roadshow in London

Last Tuesday I travelled to London to attend the AWS Dev Day Roadshow in London, where I'd be learning all about the intersection between Chef and AWS.
Neither I nor my employer, Capital One, are AWS Partners, so didn't receive any information about it through those channels. Instead, I found out about the event through a targeted Twitter ad, which has made me conflictingly rethink whether I should keep adblock or not.
The day was a mix of information via slideshows and a practical demo from Jonathan Weiss and Darko Mesaroš from AWS and Tom Robinson-Gore from Chef. During the practical section we used AWS CodeCommit and CodeBuild to manage the Source Control and pipeline of a Chef cookbook, which ran linting via chefstyle and foodcritic, and further testing with Test Kitchen. Upon success, there was a manual approval step, also via CodeBuild, upon which it would push the cookbook to our Chef Server, managed through AWS OpsWorks.
Although I'd misjudged the level of knowledge required, as well as coming in with very little knowledge about the event due to no agenda or information being published, I had a great time as I got to play around with OpsWorks (which I had recently been pondering) and was able to see the Chef Automate platform in action!
State of the Union
We started off by hearing from Jonathan about how Amazon has changed over the last 15 years, starting with a monolithic C binary that was literally gigabytes in size, which adhered to a fixed release cadence and a lot of complaining if any team broke the release and meant everyone's work from the last week was blocked until debugging could be completed. And now they run a service-oriented architecture using microservices, with teams owning all their own processes, which allowed a whopping 1430 feature releases to Amazon customers over 2017.
It was interesting to hear how the company is actually run as hundreds of different businesses, where teams have full autonomy over delivering value to their customers (be they internal or external) in a way that they should be owning their pipelines rather than moulding the way they work to "the way" prescribed elsewhere.
Jonathan mentioned that this has led to a common experience within the AWS console UI, where there may be different UI styles between pages. This happens due to teams deciding that they prioritise feature releases over consistent UI, with the aim to pick it up after more important features.
Pessimistic Deployments
One key learning over this migration to microservices was that although there was a drive to build confidence in their release process, they had resigned themselves to realise that there would always be something they missed in their quality gates or release readiness, regardless of best intentions. The idea that there would always be a non-zero possibility of negative effects in a release; you may as well prepare for it rather than be surprised when it happens.
This led them to the use of Pessimistic Deployments which ties caution with continuous monitoring:

This approach ensures that the minimal set of customers are affected, and that at any point, it can be rolled back to prevent further impact.
By starting with deploying to a single box in production, there will only be a small amount of traffic across the whole set of infrastructure that is using the new version. That change can sit on the box for some time, allowing monitoring in terms of latency, errors, and other system/business metrics.
Once happy with how that box is responding, other instances in the Availability Zone can be deployed to, while monitoring for any implications before moving on to another AZ. In the next AZ, comparisons can be made against the previous AZ - for instance, is the latency the same? Or is the new AZ degraded?
Once all AZs in the first region are migrated, the next region can be deployed to, again starting with a single box, and slowly increasing load while monitoring compared to the previous region.
Application vs Infrastructure
Jonathan discussed some differences that AWS see around key components in a piece of software, and how they largely split into two:

The reasoning for this is that the actual code you write and the configuration for it (be it configuration files, environment variables, or Chef code) is one piece, which is the piece that you fully own. However, the infrastructure, such as where the code sits isn't entirely under your control, i.e. someone else may create your AMIs.
In line with this, they also see a matching split in pipelines, with the aim to automate the whole release process:
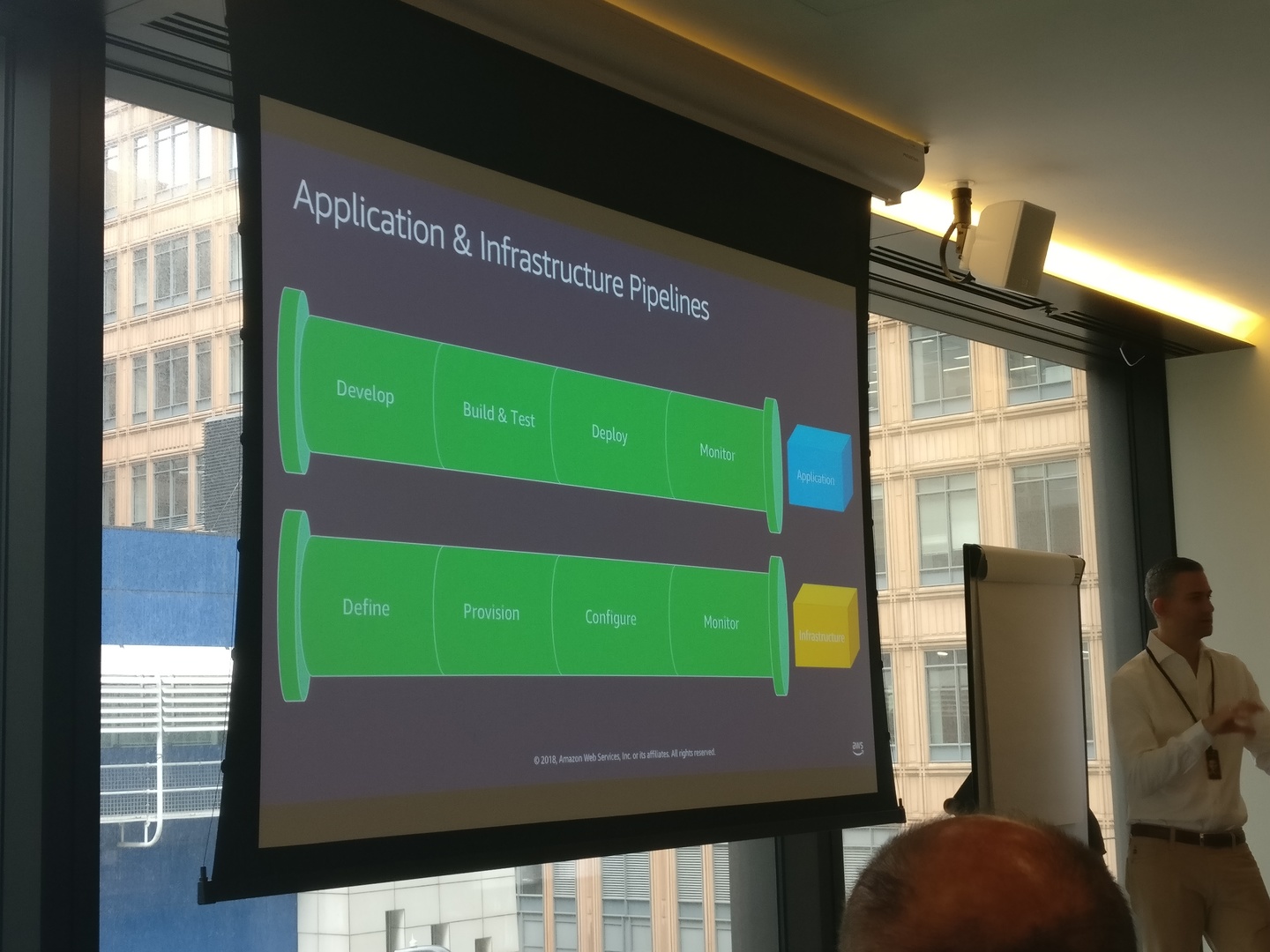
Application pipeline (i.e Java code, relevant configuration such as cookbooks):
- Develop: Code is built by developers, pushed to Source Control Management
- Build & test: Ensure code can i.e. compile, pass lint, unit tests
- Deploy: Push into the infrastructure
- Monitor: Ensure it's performing however you need them to
Infrastructure pipeline (i.e. AWS services, maybe DNS or Proxy):
- Define: "What services do you need?"
- Provision: Get the services running
- Configure: Tweak them as you need, for your workloads
- Monitor: Ensure they're performing however you need them to
There could also be pipelines for your compliance, security, policies or canary deployments, as well as many others depending on how your organisation works.
An Introduction to CloudFormation Templates (CFTs)
Darko started off by explained how CFTs were of use and what a template looked like. This gave some context for those in the group who weren't as experienced with the AWS Cloud.
It helped frame how, when you're building a new service, you have a number of factors to plan for:
- security aspects
- network design and topology
- application design
- infrastructure design (i.e. Load Balancers)
Once the designs are in place, you still have the task of building it, which can be quite repetitive, so you'd want a way to easily duplicate your designs, in a form that is easily versionable. This is something that CloudFormation can excel at, with a self-documenting syntax, and leveraging Parameters for customisation.
An Introduction to Chef
Tom explained what Chef was, and how it could be used for an array of business needs:
- lifecycle post-provisioning for i.e. an EC2
- patches + update lifecycle
- installing software
- updating configuration files
- managing access to nodes (something that Chef runs against, i.e. an EC2, physical server, VM, container)
- enforcing compliance across the fleet
He shared how Chef was used to describe the "desired state" of a node in a human-readable way using a Domain Specific Language on top of Ruby. However, because it's Ruby under the hood, it is possible for developers to use Ruby where more power or control is needed than Chef provides out of the box.
One interesting feature of Chef is that it's built to idempotent. It means Chef can be run more than one time on the same node, but always end up in the same desired state. This allows scheduling of a Chef-client run at i.e. 30 minute intervals, ensuring that your nodes don't have any configuration drift, such as someone logging onto the node and changing debug logging, or adding their own SSH keys.
AWS OpsWorks
AWS OpsWorks is a fully managed Chef Server, with the additional functionality of Chef Automate. It makes it easer to get up and running with Chef and makes it possible to focus on getting applications running.
Note that the Chef Server itself is Apache 2 licensed and can be run separately from Chef Automate, which is not required in order to run Chef in your organisation. The server does, however, require work to install, tune, and then the extra overhead to run, which at the start of your Chef journey can be extra hassle you don't want to bother with.
One distinguishing factor is the "Starter Kit" it provides, which is bundled with the private key for connecting to the Chef server, as well as a userdata.sh and a userdata.ps1 to point directly to the Chef Server's FQDN. This means you can pull down that zip as part of your EC2's user data, specify which role/cookbook(s) to run, and you're good to go.
As it's a managed server, it includes the necessary work to configure backups and automated restoration (a touted 12 minute restoration process), perform automatic security upgrades, as well as getting AWS' service reliability. In line with regular AWS pricing models, you simply pay the EC2/S3 cost for the server, and a pay-as-you-go model for each Chef node connecting to Chef Automate. This makes it easier to get started with Chef Automate, meaning you don't need to buy a tonne of licenses up front!
As an AWS service, it heavily integrates with IAM policies for access control, as well as allowing SAML logins to utilise an organisation's existing Identity Provider.
An unfortunate issue with the current architecture of the OpsWorks is that it can't be set up in a true Highly Available setup, but can be hacked around in order to resemble one. The recommended solution is to run two OpsWorks servers, and have nodes connecting to either instance. However, this means that you will have a much harder time determining which of your fleet are connected where, and also have two Chef Automate dashboards, which may be less than ideal.
Chef Automate
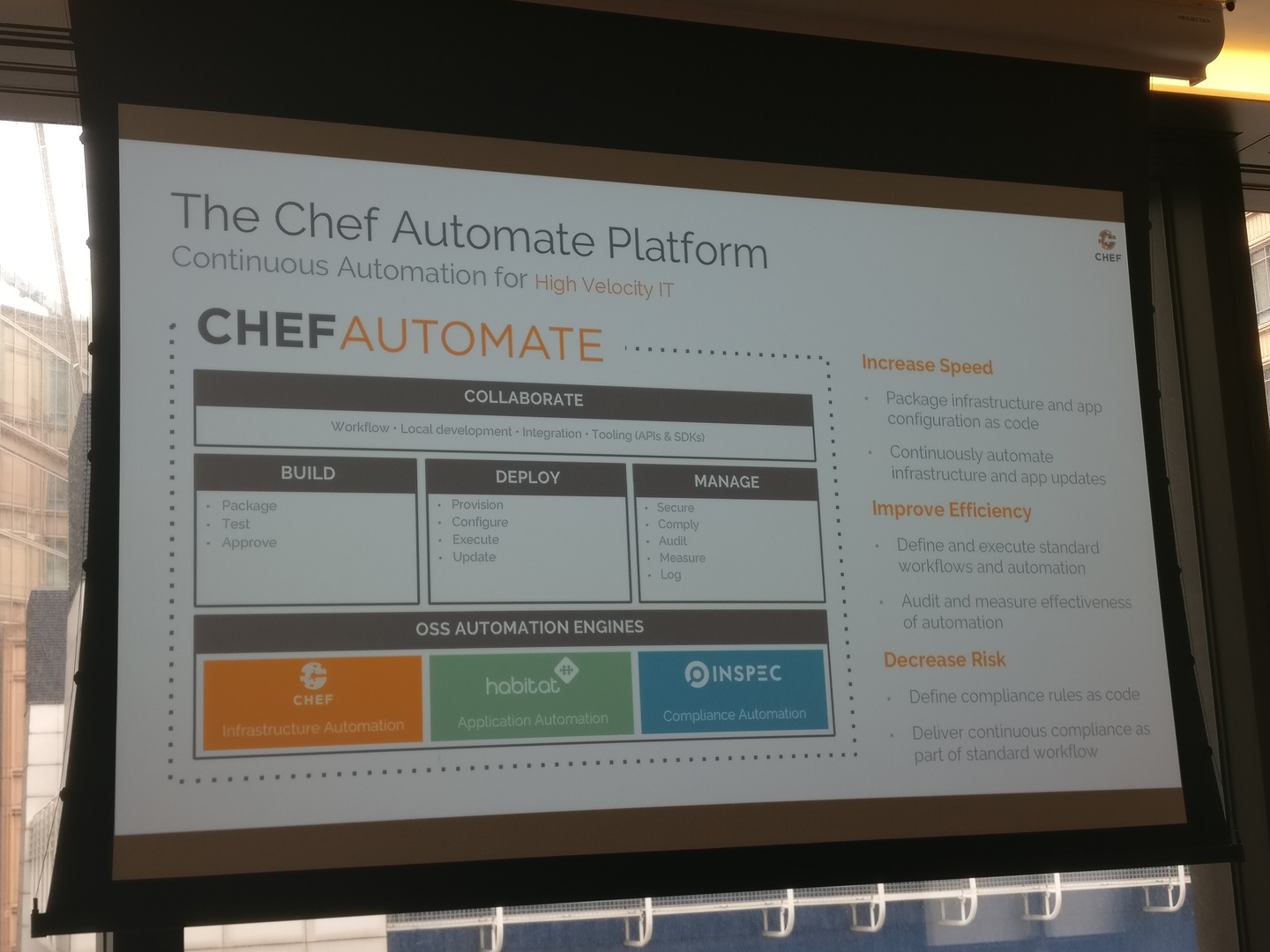
It was my first time seeing Chef Automate, which has some great visualisation over the nodes you had in your Chef environment(s), the breakdown of platforms and versions, as well as which nodes have been having issues converging. It also uses InSpec and audit cookbooks under the hood to ensure that your environment is compliant. This can be configured against any number of pre-defined compliance profiles (such as CIS hardening policies) or you can create your own using InSpec controls. Again, these visualisation tools can help you spot any new configuration drift and work out the health of your fleet.
These mappings of compliance can help you meet your organisation's internal policies around not only general and data security, but also fit within any regulatory requirements that your business needs to fulfill.
Elephant in the room - Containers / Serverless
A common question Darko regularly receives is "where does Chef come in with containers?", to which he pointed us to watch the keynote of ChefConf 2018, in which Arun Gupta of AWS talks about how Chef usage will change.
One key point is that even though you're deploying containers, the node you're deploying to will need some configuration. So even if no application developers need to understand how Chef is used, there will still be infrastructure or middleware teams who will. There will also need to be requirements around security and compliance for those nodes, such as SSH hardening, as well as providing correct privileges to i.e. your system administrators so they're able to debug if needed.
This is targeted by InSpec, the Open Source compliance tool Chef Software builds, which can now interface with containers for that very reason.
A note from me is that this is not quite true on a hosted container platform, such as Google Kubernetes Enginer or AWS Fargate, nor when working on a "Serverless" platform such as AWS Lambda. In these cases, provisioning is mostly unnecessary, which means tools like Chef will lose their edge.
"Enterprise as code"
A term I'd not heard used before, but which I quite like is "Enterprise as code":

Where
- infrastructure is i.e. an EC2, an ALB
- configuration is i.e. anything on that EC2 i.e via Chef
- operations i.e. patch management, incident management
- compliance i.e. which ports are allowed to be open
Not only should (in an ideal world) these all be in an easily machine-readable format, such that tools can take advantage of policies and configuration, but they should be built independently - for instance, changing the directory that Apache installs to shouldn't mean your CloudFront distribution should need to rebuild.
Inspec
InSpec is a compliance tool built by Chef Software, aiming to shift left the risk of finding compliance issues - from runtime to the build/test phase. InSpec 2 also brings the ability to test databases for i.e. overly open access controls, or verify that cloud infrastructure i.e. doesn't allow incoming traffic from any location.
InSpec is built to manage policies, such as audit logging always being enabled and pointed to the correct place or that you don't accidentally install non-headless versions of Java. These profiles should be built in conjunction with the Security/Operations teams, so that you can find the common ground. Once the profile is created, teams enter the detect-correct loop, where non-compliance can be found, a patch pushed, and repeated until all non-compliance is resolved.
A great starting point for InSpec profiles would be having a passive "patch baseline" profile running, which can start to point out non-compliance across the fleet. Unfortunately it's more than common, given the out-of-the-box AMIs on Amazon fail the compliance checks! So custom work on top of that may not pass either. Tom mentioned that Chef are currently writing cookbook(s) to remediate the findings, although it wasn't quite clear whether these would be available to the community, or if it would only be for Chef Automate customers.
Two main repos that are of interest are:
A recent finding of mine was that it is built as an agent-less tool with no extra dependencies to pull onto the box. This is great, because you wouldn't want to have your production box, that you'd tested carefully and ensured you only installed what you needed, suddenly pulling down a tonne of new dependencies just to ensure it's secure.
Other interesting tidbits
There were a number of other gems of knowledge that weren't part of the official planned day, but I wanted to capture as they were of interest.
taskcat
Mentioned in passing, taskcat seems to be a tool to help with testing CloudFormation templates by deploying them against multiple Availability Zones and Regions.
AWS On-Prem Services
I'd not heard before about AWS Snowball, an appliance to help migrating "petabyte-scale data sets into and out of AWS". As I'd not considered the work that must be required to migrate over large datasets to the cloud, this was new information to me - but it makes a lot of sense.
AWS CodeDeploy also appears to be able to run on-prem with a licensed agent-based setup, allowing an organisation to deploy to either on-prem or cloud instances.
AWS OpsWorks is also able to work with any on-prem nodes you have, as long as there is network connectivity, which means it can be much easier to manage both sets of infrastructure while migrating.
Node de-registration
Chef Automate/Server isn't actually aware of when an instance has i.e. had network traffic interruption, or when it's been destroyed. This means that there are manual steps required to perform cleanup on i.e. EC2s being destroyed in the AWS account.
AWS Systems Manager
Another service I hadn't heard of before is AWS Systems Manager, which makes operations easier by adding visualisation on top of groups of resources. An example we were given was the case that you had a known memory leak in your Tomcat servers, and that the trick was just to restart Tomcat when nearing memory limits.
CloudFormation Template Visual Designer
Although it's not something that I'd generally find myself using, the fact AWS have built a visual designer for CloudFormation is pretty cool, as you can take any pre-written CFTs and it can generate you a clear architecture diagram.
VSCode Plugin
Darko showed us the CloudFormation plugin, which provides autocomplete for CFTs, as well as being aware of the properties for a i.e. an EC2 resource. Although not a VSCode user, it's definitely piqued my interest to looking at what plugins Vim has for writing CFTs.
berks install vs berks vendor
Tom mentioned that berks install pushes the cookbooks into the main Berkshelf directory, for instance $HOME/.berkshelf/cookbooks, whereas berks vendor wibble creates a bundle of cookbooks in the folder wibble.
Capital One Cloud Custodian
On the topic of Cloud compliance policies, I thought I'd be remiss not to plug Capital One's Cloud Custodian tool. It started as an internal tool, but has since been Open Sourced as it's helped make managing our cloud infrastructure across the enterprise much easier, because it can check things like:
- oversized EC2s being used
- AMIs not being updated
- blocking an instance from starting up with a public IP address
- S3 buckets being created with overly open read ACLs
